一、关系性数据库
关系型数据库主要有以下三个特征,尤为明显,如果没有这个三个特征约束,当多个客户端使用数据的时候就会出现各种各样的错误,所以关系型数据库定义这些约束,让客户端程序只要遵守这个规则便可以规避很多的错误。
这三个特征主要是:
- 强类型
- 引用完整性
- 事物
1、强类型:
大多数的数据库都是强类型的,要求数据库引擎严格执行,引擎通常定义一些原生的数据类型,它描述可以存进数据库当中数据的具体类型,这些类型通常是各种长度的浮点数,字符串,整数等,特定的实现,这个类型不能让用户自己特定的去扩展,当引擎定义了关系,数据库当中将无法企图把错误的数据类型的数据存入列当中,
例如:尝试插入一个包含一个字符串作为第三个特性的元组到一个指定第三特性应该是一个浮点数的关系当中,通常引擎会报错,将插入失败。
2、引用完整性
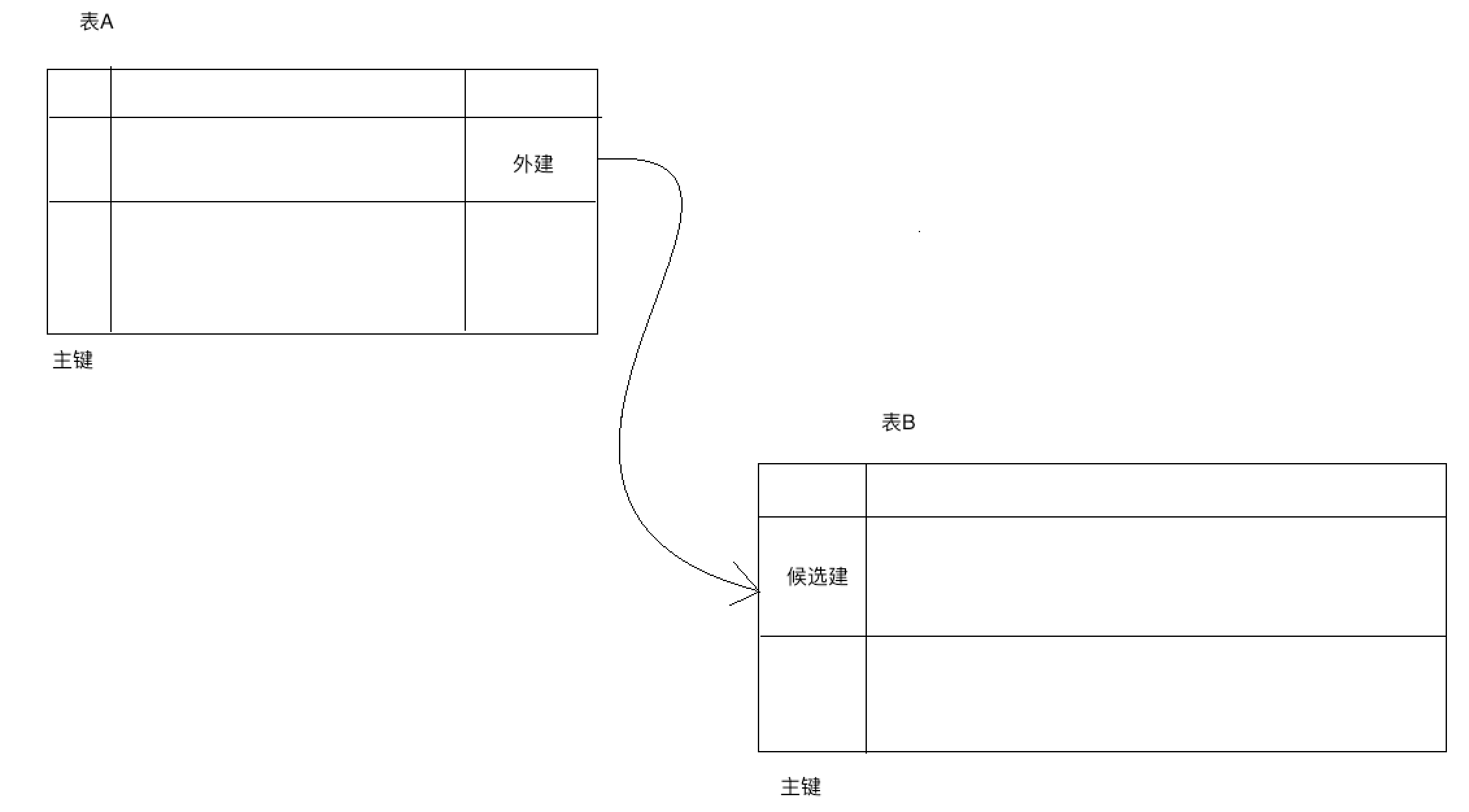
在关系型数据库当中,原生类型可以通过声明一个关系中的列到另一个关系的一个引用进行扩展,也就是我们常说的主外建关系,数据库架构师可以声明一个关系中一些列的内容是其他关系中类似类型列的一个引用,下图进行外建的演示:
上述就是最简单的主外建关系,通过表A当中的外建和表B进行连接,从而如果可以在表A当中获取到数据就可以在表B当中进行查询,
想要实现上述的要求,必须遵循数据库引擎提供的引用完整性,因为数据库引擎将会强制的去执行引用完整性约束,该约束主要分为以下的两种类型,
2.1 强制会去执行表B的主键约束,就如上述表B当中的主键。要保证在表B当中主键列当中主键的唯一性,也就是不可以重复,例如当表B当中的主键有A,B,C三个值,现在插入一行数据的主键列为A或B或C将会失败,因为破坏了主键约束的唯一性。
2.2、强调表A的引用完整性,所谓什么是引用完整性呢,就是表A当中的外键要么是null,要么该指就一定在表B的主键当中存在,下面有两种情况会破环引用的完整性,
- 如果给表A当中插入一行数据,该数据的外键值在表B当中没有,那么该操作则失败。
- 如果删除表B当中的一条数据,并且该条数据被表A当中的外键所引用,那么该操作失败
上述两种情况也是我们开发当中常常会用到情况,所以我们的解决方式便是,
- 先插入表B当中的数据,然后插入表A当中的数据
- 先将表A当中引用表B的外键值置为null,然后删除表B当中数据
3、数据库事务
事务:对数据的一组操作当作为一个单位去执行,要么全部失败,要么全部成功。事物有以下几个特点,常常被开发者侃侃而谈,便是
- 原子性:全部成功,全部失败,操作被视为一个单位,不能将操作分离
- 一致性:事务开启之前,数据库处于有效状态,那么事务开启之后,数据库仍然处于有效状态,不能因为事物导致数据约束被破坏
- 隔离性:执行完事物以后,数据库的状态可以通过依次执行事物中的命令达到同样的状态
- 持久性:事物一旦完毕,就不能丢失,比如电源故障等,物理环境都不能撼动。
二、SQL语言
什么是SQL语言呢,就是操作数据库以及数据库当中的数据的命令。称之为SQL语言,SQL语言是由数据库引擎解释并且执行的,SQL语言大多数开发者都或多或少的已经掌握,所以该部分内容为回顾内容,笔者并不打算详细讲解。如有不同,可以自行Google,Baidu。
SQL语言主要分为六大类,分别是DDL(date definition Language)数据定义语言、DML(Data Manipulation Language)数据操作语言、DQL(Data Query Language)数据查询语言,TPL事物处理语言,DCL数据控制语言、CCL指针控制语言。
其中最为常用的便是上述当中的前三类语言,而后面的三类用的不是很多,所以对前三类语言做详细介绍,而后面的三类简单了解就可以了。
1、DDL(数据定义语言)
主要描述的是数据库当中所包含的数据结构,最常见的DDL语言就是用来定义一张表,包含列数、列类型、还有删除一张表,下面为创建一个User表的SQL语言描述。
删除表结构
DROP TABLE users;
创建一个新的表结构
1 | CREATE TABLE users{ |
这里需要注意的是:在定义一张表的时候,所有数据库语法的关键字大写,并且列名称是唯一的,这里不允许列名称之间相互重复。并且表的名称在同一个数据库当中也不能重复,通常使用的是一个复数名词
除了创建表以外,SQL的DDL允许创建其他标准的RDBMS的数据结构,而RDBMS当中常见的标准的数据结构除了相应的表以外,还有相应的视图(View)、触发器(trigger)、索引(index)。这里把定义一个给定数据库当中所有对象的DDL语句集合叫做这个数据库的模式(schema),其他的数据结构在什么场景下会用到呢?它们分别扮演着什么样子的角色呢,
- 视图(View):
- 触发器(trigger):
- 索引(index):
2、DML(数据库操作语言)
这类型语句主要操作的是数据库当中数据的变化,有三个类型,分别是插入语句(insert),删除语句(delete),修改语句(update)。下面我们对上述定义的表结构进行数据上面的操作
插入语句
1 | INSERT INTO users( |
更新语句
1 | UPDATE users SET starred=1, has_phone_number=1 WHERE _id=3; |
删除语句
1 | DELETE FROM users WHERE _id=2; |
注意:插入数据的时候,一般要主要强类型的问题,而也要关注主键为NULL以及主键重复的问题(自增长可以解决),还有就是如果字段通过NOT NULL修饰的时候,一般会在定义表结构的时候会给出相应的默认值。
3、DQL(数据库查询语句)
查询语句是最难的,也是使用最为平凡的语句,在关系术语当中,查询创建一个新的关系(通过一个虚拟表),即就是一个或者多个表的叉积的投影约束,具体的查询语句该怎么写请各位看客自行Google,或者baidu,如下所示一个查询示例,
查询语句
1 | SELECT rc.display_name, u.starred |
连接是两个表的叉积的重要凭证。两个表的一个完整叉积把1个表的每一行于第二个表中每一行进行合拼,在上述的语句当中,users表于raw_contacts表进行连接。叉积的结果将有C(users)*C(raw_contacts)行。
完整的叉积有时候不是非常有用,在查询中 ON字句限制只有name_raw_contacts_id列的值和raw_contacts表中_id列的值相等的时候进行叉积,连接所产生的新的关系包含users表当中的行加上raw_contacts表当中的相应信息。这就非常有用了,下面有一个关于叉积理解的图,相信大家会理解什么是叉积的概念
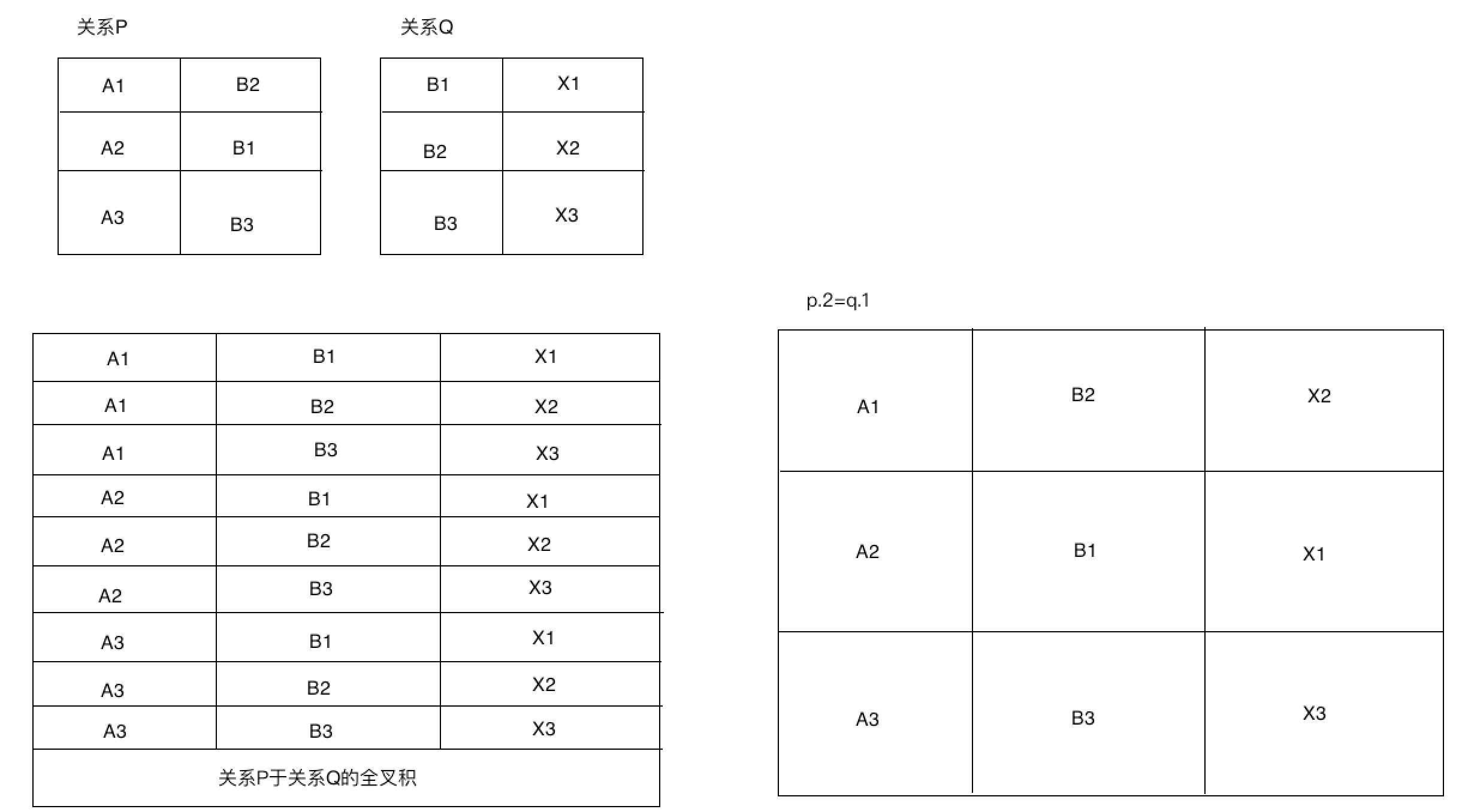
根据上述的这个小示例,我们很快就会明白多表查询的原理是什么,主要就是通过条件去约束叉积,然后拿到我们想要的数据。到了这里,基本的SQL语言也就差不多了,剩下三种语言类型,我们可以仔细看我的XXXX博客仔细研究。
三、SQLite入门
Android端使用的数据库就是开源数据库SQLite,它是一个小型的无服务器的数据库,由于这种数据库的种种特性,让它成为了在手机端极具吸引力的数据库之一,大体说一下都有什么好处,让该数据库这么火热,
该数据库是2000年开发的,当初开发的初衷就是轻量级方式管理结构话数据,所以非常的轻便,具体的优点有以下几点
- 存储在里面的数据持久化的跨进程和电源存在。
- 跨越系统软件升级和重新安装
- 处理多种异常情况,非常优雅,比如:低内存环境、磁盘错误、电池电量不足、都不足矣破坏已经持久化的数据
当然缺点同时也是存在,关系数据库的几个重要特征部分丢失,SQLite当中没有强类型的支持,虽然有引用完整性的支持,但是默认是关闭的,唯独事务默认情况是开启的。
SQLite数据库其实就是一个文件。在Android设备当中大多数应用程序把数据库存储在文件系统沙箱当中,位于名为datebase的子目录当中,例如对于包是com.suansuan.application的应用程序,其数据库极有可能位于目录/data/data/com.suansuan.application/datebases中。
在以前人们想象能否将数据库放入到SD卡下,让其自己应用程序的数据库被多个程序所共享,但是相比于这么做Android提供了更好的解决思路。
1、SQLite语法
命令行当中是用sqlite3的时候,首先要记住每条命令必须以分号结束,就和我们写代码的时候一样。
当然还有一些命令,我们称之为元命令,这些命令不属于数据库所有,而是SQLite3去解释与执行,这些命令都是以,开头的命令,其中最常用的就是.help和.exit .schema命令
其余的就是常用的SQL命令了,当然也可以叫做SQL语句
2、支持的数据类型
前文已经说过SQLite数据库当中没有强引用的支持,实际上列的类型仅仅只是注释,列的类型仅仅只是提示而已,以帮助SQL引擎为此刻存储在该列的数据选择高效的表示。SQL引擎使用一些简单的规则来调节“类型相似性”,从而决定内部存储类型。这些规则几乎不可见,我们开发能感觉到的是给定数据集占用的磁盘数量而已。
实际开发当中,Google开发人员限制自己只使用SQLite的4种基本类型,(integer、real、text、blob)并且显式的使用文本来表示时间戳,使用integer来表示boolean值。
我们通过一个例子,来了解SQLite当中的“类型弱化”
1 | sqlite> create table test( |
3、关于约束
3.1、主键约束
我们可以将列的约束定义在表结构当中,比如我们常常用来修饰主键的 PRIMARY KEY的约束,唯一,表示这一行。同时SQLite支持非整数主键、支持多列复合主键,这里需要注意一下,关于非整数主键,除了“唯一”约束以外,应该还存在“非空”约束。但是由于SQLite早期版本的疏忽,SQLite允许Null作为非整数主键。所以会出现很多行主键为NULL的情况(此NULL非彼NULL),从而我们需要使用代码给插入数据的主键做非空判断,要不然我们数据库当中就会出现无法通过其主键都无法区分的数据,笔者这里把这些数据叫做“脏数据”
通过上述的问题,很多开发人员都使用integer来做为主键列,同时将主键设置为自增长,PRIMARY KEY AUTOINCREMENT。并且SQL引擎为了解决上述问题,会默认的在表当中加入一个隐式的id,
关于自增长,我们可以通过下面示例来了解
1 | sqlite> create table test( |
自增长非常好用,可以唯一表示我们的数据,并且我们都不用去关心,但是正是因为我们的不关心将导致大量丑陋且愚蠢的代码存在,比如我们添加一个新行,并且需要将新行的id存储在SP当中,以便下次快速访问,这种情况下,各位看客想想该如何实现呢。其实笨办法确实有,并且笔者只想到了一种,如果看客有好的想法可以下方留言,那就是再查一遍,
3.2、外键约束
上文提到过外键约束,SQLite不强制执行外键约束,其实和SQLite列类型类似相似本质上都是注释,但是可以通过修改相应的属性来让SQLite强制执行外键约束
pragma FOREIGN_KEYS=true
通过上述指令开启外键的引用完整性。
下面我们来看一下关于外键注释:
1 | sqlite> creaet table people( |
上述语句,如果是在支持引用完整性的数据库当中,第一个insert将失败,并且第一个create table people也将失败,因为找不到addresses这个外键表,很显然上述我们的试验都成功了,也就意味这SQLite数据库不会去强制执行外键约束。
但是SQLite的优点就是灵活方便,如果我们需要设计一个复杂类型的、并且多个表通过外键所连接,像这种时候,易于修改和高效的数据存储反而成为了SQLite的闪光点,Google官方文档中描述,鼓励开发人员使用标准范式,然后让开发这自己编写代码的时候自己规划引用完整约束,而不是依赖数据库去实现。
下面我们来模拟一个简单的连接
1 | sqlite> create table people( |
SQLite中还支持一些其他的约束,比如:
- unique:该约束表示SQLite将拒绝任何试图在表中添加将导致该列出现重复值的一行。
- not null:该约束表述SQLite将拒绝任何试图将表中数据置为NULL的所有操纵。
- check(expression):当次约束修饰列时,每当一个新行添加到表中时,或当修改现有的行时,都会对表达式求值,如果求值的结果转化整数为0时,该操作将失败,操作将取消。如果表达式的计算结果为NULL或者任何其他非零值,则操作成功
下面展示一个列约束:
1 | sqlite> create table test( |
4、SQLite数据库示例
在开始我们的程序示例之前,我们需要对我们数据库当中的数据进行一些格式化,好方便我们之后的查看数据。使用SQLite的元命令来进行数据库数据展示的格式化。
1 | sqlite>.header on |
具体详细内容,可以参考SQLite元命令http://www.runoob.com/sqlite/sqlite-commands.html
我们来尝试去创建一个完整的User的数据库。
1、创建User表
1 | sqlite> create table users( |
我们需要一个字段是用来记录这条记录是什么时候被修改的,好方便我们以后对数据的修改
1 | sqlite> alter table users add last_modified_time text; |
2、创建触发器
我们让刚刚我们定义完的字段,可以根据我们插入数据,或者是添加数据跟随我们插入数据和更新数据取当前最新的时间。这里定义两个触发器,一个是跟随insert所进行触发,一个根据update进行触发。
1 | sqlite> create trigger t_users_audit_i |
上述触发器创建的时候用到了datetime数据库内置和日期相关的函数。具体内容可以查看http://www.runoob.com/sqlite/sqlite-date-time.html
现在我们插入一条数据来验证我们刚刚创建的结构是否正确。
1 | sqlite> insert into users(name) values("liupengcheng"); |
我们的User可能需要地址,比如客户的收货地址,所以我们创建一个地址表,
1 | sqlite> create table addresses( |
如果我们引用完整性的支持已经开启的话,这个表的定义肯定会导致一个错误,因为这里cities这张表是不存在的。不过在SQLite数据库的默认配置当中,是没有问题的,我们可以稍后去定义cities这张表。
现在我们的用户存在了,地址表也存在了,这里分析得到,一个用户可以有多个收货地址,一个收货地址可以被多个人多共有,所以这里的关系是多对多,一般的主外键支持一对多,如果是多对多的关系的话,我们就需要建立第三张表专门的让上述两张表进行对应了。
1 | sqlite> create table users_addresses( |
现在我们来我们创建的数据库添加数据
1 | insert into users(name) values("wangyiqi"); |
现在数据也有了,关系也键全了,现在可以使用关联关系进行查看我们之前所编辑的数据实体了。
1 | sqlite> select name,street,number from users,addresses,users_addresses where users._id = users_addresses.users and addresses._id = users_addresses.address; |
如果我们想确定一个地址下面有多少用户,我们可以使用count函数和group by字句来实现。
1 | select count(name),number,street |