- 1、享元模式的作用
- 2、享元模式的使用场景
- 3、享元模式的UML类图
- 4、享元模式Demo
- request的缓存池
- result的缓存池
- JDK当中的常量池
1、享元模式的作用
享元模式实际上就是对象的缓存池,英文为Flyweight,目的是尽可能地减少内存的使用,来缓存大量重复对象的场景,来缓存可共享的对象,避免创建过多的对象的场景,来提升性能,避免内存溢出的场景。
2、享元模式的使用场景
使用享元模式的使用场景比较多,又有着显著的特点,有以下三个特点的可以使用享元模式
- 系统中存在大量的相似的对象,
- 细粒度的对象都具备较接近的外部状态,而且内部状态与环境无关,对象没有特定的身份
- 需要缓存池的场景
上述说到相应的外部状态,内部状态,这两个状态,我们建立自己的缓存池的时候,一般使用外部状态,也就是这个对象会随着变换的那个状态,做为一个key存储在一个map当中,或者使用list当中,使用list的时候,相应的inedx便是该对象为一标示的外部状态,当然了,有时候需要我们自己来维护,相应的index到外部状态的一种映射。注意;在使用享元模式的时候,一定要明白什么是外部状态,什么是内部状态。这个搞清楚了,这种模式也就相应的搞定了
3、享元模式的UML类图
为了让这一种设计模式看起来更加的易于理解,所以这里使用UML来描述该设计模式。
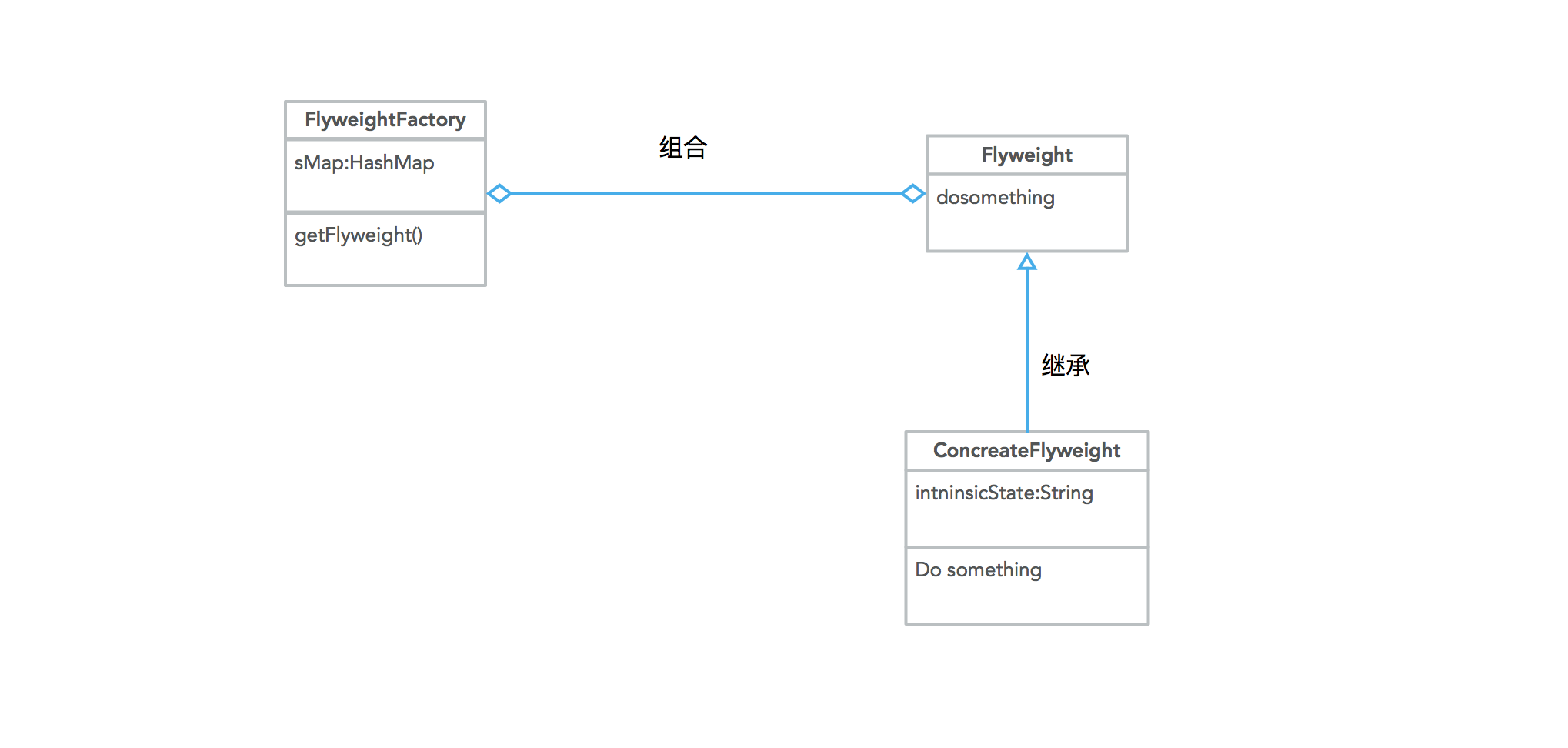
4、享元模式的Demo
4.1、请求缓存池
例子:客户端的程序设计一般都是含有相应的网络请求模块的,本地请求服务器拿到相应的数据,然后显示这些数据。现在有这样一种情况,当客户端请求服务器,如果相同的请求,一下就请求了100次,或者上千次,或者相同的请求只是参数不同,然后请求了很多次。
如果一个请求在我们的程序当中就是一个对象的话,当我们请求的时候,我们就需要new出来一个请求的对象,然后在我们请求完毕以后,由GC销毁。很明显上述的这种情况不是一种合理的解决方式,其实如果我们代入相应的享元模式的话,就会发现其实很简单。具体的相应实现如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
public class Request {
private String url;
private int offset ;
private int total ;
public Request (String url, int offset, int total) {
this.url = url ;
this.offset = offset ;
this.total = total ;
}
public void setParams (int offset, int total) {
this.offset = offset ;
this.total = total ;
}
@Override
public String toString() {
return "Request [url=" + url + ", offset=" + offset + ", total=" + total + "] = " + Integer.toHexString(hashCode());
}
}
public class RequestFactory {
private static final Map<String, Request> sMap = new HashMap<String, Request>();
public static Request getRequest (String url, int offset, int total) {
Request request ;
if (sMap.containsKey(url)) {
request = sMap.get(url);
request.setParams(offset, total);
return request ;
}
request = new Request(url, offset, total);
sMap.put(url, request);
return request ;
}
}
public class Main {
public static void main(String[] args) {
int offset = 0 , total = 0;
Request request0 = RequestFactory.getRequest("http://test.test.test", offset, total);
System.out.println("request0 = " + request0);
Request request1 = RequestFactory.getRequest("http://test.test.test", offset + 100, total + 10);
System.out.println("request1 = " + request1);
Request request2 = RequestFactory.getRequest("http://test.test.test", offset + 200, total + 20);
System.out.println("request2 = " + request2);
System.out.println(request0 == request1);
System.out.println(request1 == request2);
}
}
|
request0 = Request [url=http://test.test.test, offset=0, total=0] = dcf3e99
request1 = Request [url=http://test.test.test, offset=100, total=10] = dcf3e99
request2 = Request [url=http://test.test.test, offset=200, total=20] = dcf3e99
true
true
通过上述的Demo,我们确实发现了,使用的都是一个对象,当然我们只是一个简单的例子,比如,如果前一个对象还没有使用完毕,我们在创建第二个对象的时候改变了上一个对象的状态,导致第一次查询的时候拿到是offset=100 total=10的情况,所以后续还需要我们优化。
4.2、result缓存池。
我们去数据库当中查询数据的时候,有时候会遇到多次查询相同的数据,这样的话我们把查询结果result至于缓存池当中,就不必多次去数据库当中查找了。
下面就以查询火车票为例子,假设从A到B只有一趟列车,而列车的席位有硬卧上铺、硬卧下铺、坐票三种。下面我们来看这个Demo是如何运作的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
package flyweight.queryTicket;
public interface Ticket {
public void showTicketInfo(String bunk);
}
public class TrainTicket implements Ticket{
public String from ;
public String to ;
public String bunk ;
public int price ;
public TrainTicket(String from, String to) {
this.from = from ;
this.to = to ;
}
@Override
public void showTicketInfo(String bunk) {
this.bunk = bunk ;
price = new Random(47).nextInt(300);
System.out.println("该买从 " + this.from + " 到 "
+ this.to + "的 " + this.bunk + " 火车票" + ", 价格为 " + this.price);
}
}
public class TicketFactory {
private static Map<String, Ticket> sTicketMap = new HashMap<String, Ticket>() ;
public static Ticket getTicket (String from, String to) {
String key = from + "-" + to ;
if (sTicketMap.containsKey(key)) {
System.out.println("使用缓存 -- > " + key);
return sTicketMap.get(key);
} else {
System.out.println("创建对象 -- > " + key);
Ticket ticket = new TrainTicket(from, to);
sTicketMap.put(key, ticket);
return ticket ;
}
}
}
public class Main {
public static void main(String[] args) {
Ticket ticket01 = TicketFactory.getTicket("北京", "西安");
ticket01.showTicketInfo("上铺");
Ticket ticket02 = TicketFactory.getTicket("北京", "西安");
ticket02.showTicketInfo("下铺");
Ticket ticket03 = TicketFactory.getTicket("北京", "西安");
ticket03.showTicketInfo("坐票");
}
}
|
创建对象 – > 北京-西安
该买从 北京 到 西安的 上铺 火车票, 价格为 158
使用缓存 – > 北京-西安
该买从 北京 到 西安的 下铺 火车票, 价格为 158
使用缓存 – > 北京-西安
该买从 北京 到 西安的 坐票 火车票, 价格为 158
4.3、JDK当中的常量池
我们知道一个String对象是被存储在常量池当中的,也就是说一个String被定义以后,就被缓存在了常量池当中,当其他地方要使用字符串的时候,则直接使用的是缓存,不会重复创建对象,我们通过一个简单的Demo来看一下这个机制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class Main {
public static void main(String[] args) {
String str1 = new String("abc");
String str2 = "abc";
String str3 = new String("abc");
String str4 = "ab" + "c";
System.out.println(str1.equals(str2));
System.out.println(str1.equals(str3));
System.out.println(str1.equals(str4));
System.out.println(str2.equals(str3));
System.out.println(str2.equals(str4));
System.out.println(str3.equals(str4));
System.out.println("========");
System.out.println(str1 == str2);
System.out.println(str1 == str3);
System.out.println(str1 == str4);
System.out.println(str2 == str3);
System.out.println(str2 == str4);
System.out.println(str3 == str4);
}
}
|
其实我们大部分都知道它的原理是什么,唯独str2 == str4 这个优点模糊,为什么会是true,其实只要代入本设计模式之前说过,常量池的概念,应该可以很容易的理解,就是str4使用的是str2的缓存对象 。